MySQL为什么有时候会选错索引?
🌰:
我们先建一个简单的表,表里面有a、b两个字段,分别建上索引;
1 |
|
然后,在表t中插入10万行记录,取值按整数递增,(1,1,1),(2,2,2)…
插入的存储过程
1 |
|
接下来分析一条SQL语句:
1 |
|
结果就是会直接a的索引。
假如做如下操作:
这个时候sessionB的查询语句select * from t where a between 10000 and 20000就不会在选择索引a了。可以痛殴满查询日志(show log)来查看一下具体的执行情况。
1 |
|
- 第一句,是将慢查询日志的阀值设置为0,表示这个线程接下来的语句都会被记录入慢查询日志中;
- 第二句,Q1是session B原来的查询;
- 第三句,Q2是加了force index(a)来和session B原来的查询语句执行情况对比。
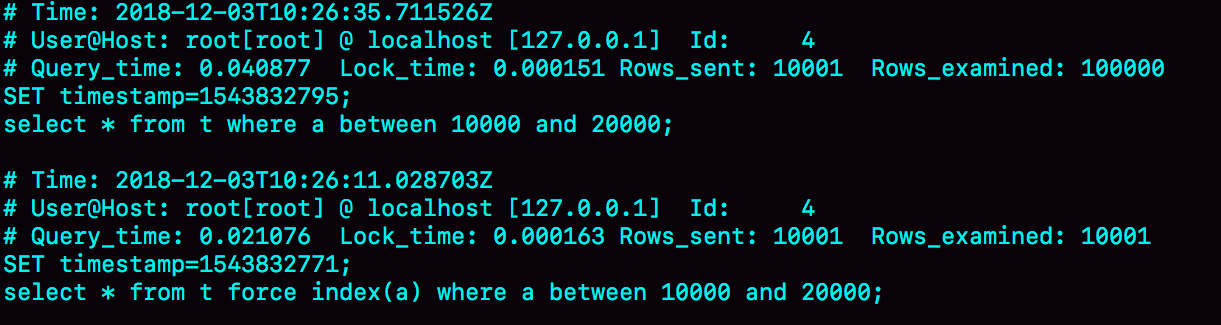
可以看到Q1扫描了10万行,显然是走了全表扫描,执行时间是40毫秒。Q2扫描了10001行,执行了21毫秒。也就是说在没有强制使用了 force index的时候,MySQL用错了索引,导致了更长的执行时间。
这个例子对应的是平常不断的删除历史数据和新增数据的场景。
优化器的逻辑
选择索引时候优化器的工作。
优化器选择索引的目的,是找到最优的执行方案,并用最小的代价去执行语句。在数据库里面,扫描行数时候影响执行代价的因素之一。扫描的行数越少,意味着访问磁盘数据的次数越少,消耗的cpu资源越少。
扫描行数并不是唯一的判断标准,优化器还会结合是否使用临时表、是否排序等因素进行综合判断。
扫描行数是怎么判断的?
MySQL在真正开始执行语句之前,并不能精确到地知道满足这个条件的记录有多少条,而只能根据统计信息来估算记录数。
这个统计信息就是索引的“区分度”。显然,一个索引上不同的值越多,这个索引的区分度就越好。而一个索引上不同的值的个数,我们称之为“基数(cardinality)”.也就是说,这个基数越大,索引的区分度越好。
可以通过使用show index方法,看到一个索引的基数。这三个索引的基数值并不同,而且其实都不准确。
MySQL是怎样得到索引的基数呢?
通过MySQL采用统计的方法来获得。
InnoDB默认会选择N个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面书,就等到了这个索引的基数。
数据表是会持续更新的,索引统计信息也不会固定不变。所以,当变更的数据行数超过1/M的时候,会自动触发重新做一次索引统计。
在MySQL中,有两种存储索引统计的方式,可以通过设置参数innodb_stats_persistent的值来选择:
- 设置为on的时候,表示统计信息会持久化存储,这是,默认的N是20,M是10.
- 设置为off的时候,表示统计信息只存储在内存中。这时默认的N是8,M是16.
其实索引统计只是一个输入,对于一个具体的语句来说,优化器还要判断,执行这个语句本身要扫描多少行。
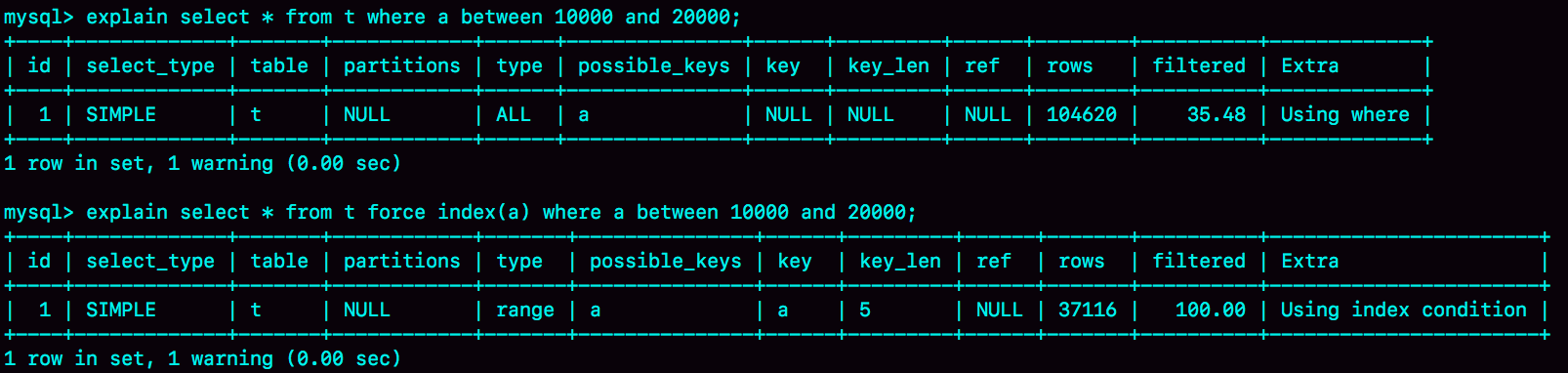
rows这个字段表示的是预计扫描行数。
其中Q1的结果还是符合预期的,rows的值是104620;但是Q2的rows值是37116,偏差就大了。而我们最开始explain命令看到的rows是只有10001行,是这个偏差误导了优化器的判断。
为什么优化器,没有选择扫描行数少的执行计划呢?
如果使用索引a,之后每一次查询都需要回表到主键索引查询出整行数据,会增加代价。优化器认为直接扫描主键索引更快。从结果来看,这个选择并不是最优的
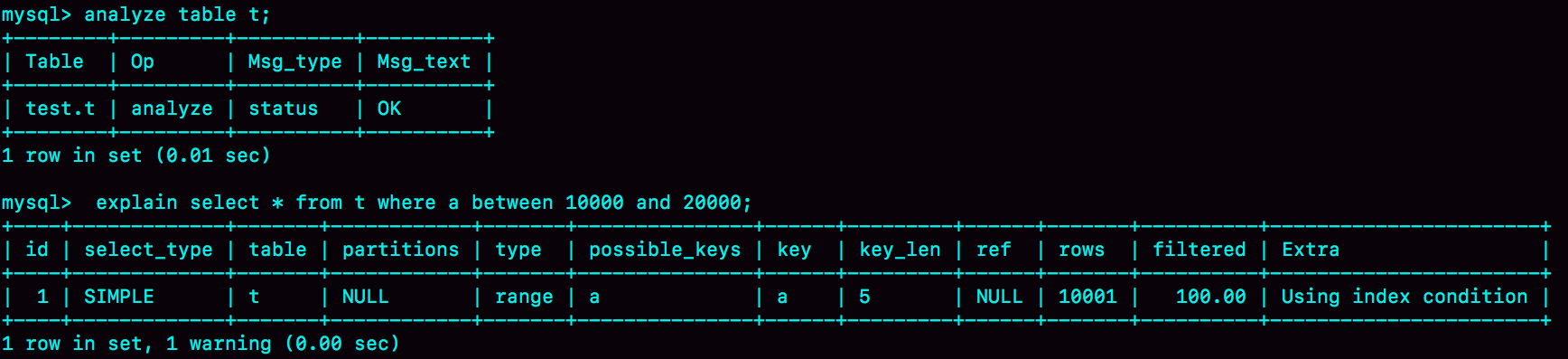
统计信息不多,就利用 analyze table t 命令,可以用来重新统计索引信息。
依然是基于这个表t,我们看看另外一个语句:
1 |
|
从条件上看,这个查询没有符合条件的记录,因此会返回空集合。
因为使用b作为排序值,所以优化器会选择b索引作为索引进行查询。
索引选择异常和处理
优化器没有选择正确的索引,采用force index强行选择一个索引。
存在问题:
- 对于代码来说存在硬编码问题,索引名字以及语法的兼容受到平台限制。
- 使用force index 一般是线上有问题再修改的过程,所以开发的时候也不会先写上。
通过修改语句,引导MySQL使用我们期望的索引。
把order by b limit 1 改成 order by b,a limit 1.语义的逻辑是相同。

之前优化器选择使用索引b,是因为它认为使用索引b可以避免排序(b本身是索引,已经是有序的了,如果选择索引b的话,不需要在做排序,只需要遍历),所以即使扫描行数多,也判定为代价更小。
现在order by b,a这种写法,要求按照b,a排序,就意味着使用这两个索引都需要排序。因此,扫描行数成了影响决策的主要条件,于是此时优化器选了只需要扫描1000行的索引a。

